您现在的位置是:首页 >要闻 > 2021-01-05 08:30:43 来源:
DUAL将AI提升到一个新的水平
韩国DGIST以及UC Irvine和UC San Diego的科学家已经开发出一种计算机体系结构,该体系结构可以更快地处理无监督的机器学习算法,同时与最新的图形处理单元相比,其能耗要低得多。关键是处理数据,并将其以全数字格式存储在计算机内存中。研究人员在2020年第53届年度IEEE / ACM国际微体系结构研讨会上介绍了一种称为DUAL的新体系结构。
“今天的计算机应用程序会生成大量需要通过机器学习算法处理的数据,”大邱庆北科技大学(DGIST)的Yeseong Kim说。
强大的“无监督”机器学习包括训练算法以识别大型数据集中的模式,而无需提供标记示例进行比较。一种流行的方法是聚类算法,它将相似的数据分组为不同的类。这些算法用于各种数据分析,例如在社交媒体上识别虚假新闻,过滤垃圾邮件以及在线检测或欺诈活动。
科学家一直在研究处理内存中(PIM)的方法来解决这些问题。但是大多数PIM体系结构都是基于模拟的,并且需要模数转换器和数模转换器,它们占用了大量的计算机芯片功率和面积。他们还可以在有监督的机器学习中更好地工作,其中包括标记数据集以训练算法。
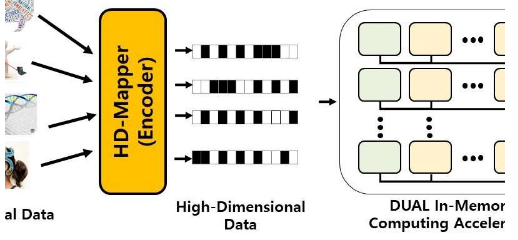
为了克服这些问题,大邱庆北科技大学(DGIST)的Yeseong Kim和他的同事开发了DUAL,DUAL代表基于数字的无监督学习加速。DUAL可以对存储在计算机内存中的数字数据进行计算。它通过将所有数据点映射到高维空间来工作。想象一下存储在人脑内许多位置的数据点。
“当今的计算机应用程序会生成大量数据,需要通过机器学习算法进行处理,” Kim说。“但是在传统内核上运行群集算法会导致高能耗和缓慢处理,因为需要将大量数据从计算机的内存移至执行机器学习任务的处理单元。”
科学家发现,DUAL与最先进的图形处理单元相比,可以使用各种大规模数据集有效地加速许多聚类算法,并显着提高了能源效率。研究人员认为,这是第一个可加速无监督机器学习的基于数字的PIM架构。
Kim说:“现有的最新内存计算研究方法致力于通过人工神经网络来加速有监督的学习算法,这会增加芯片设计成本,并且可能无法保证足够的学习质量。” “我们证明了将超维和内存计算结合起来可以显着提高效率,同时提供足够的精度。”
")





")
")
")
")
")
")
")
")
")
")