您现在的位置是:首页 >要闻 > 2020-12-17 14:28:47 来源:
研究人员开发出新的算法来训练机器人
研究实验室和德克萨斯大学奥斯汀分校的研究人员已经开发了用于机器人或计算机程序的新技术,以学习如何通过与人类教练互动来执行任务。该研究的结果将在2月2日至7日在路易斯安那州新奥尔良举行的人工智能进步协会会议上进行介绍和发布。
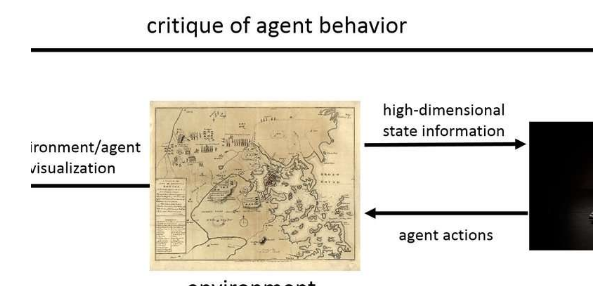
ARL和UT研究人员考虑了一个特定的情况,即人们以批评的形式提供实时反馈。ARL / UT团队首先由协作者Peter Stone博士(他是德克萨斯州大学奥斯汀分校的教授)与他的前博士生Brad Knox一起作为TAMER引入,或者通过评估强化手动训练代理,然后,ARL / UT团队开发了一种新算法叫做Deep TAMER。
它是TAMER的扩展,它使用深度学习-一类机器学习算法,受到大脑的宽松启发,使机器人能够通过与人类教练一起在短时间内观看视频流来学习如何执行任务的能力。
根据陆军研究员加勒特·沃内尔(Garrett Warnell)博士的说法,研究小组考虑了一种情况,在这种情况下,人们通过观察和提供批判来教给特工如何做人,例如“好工作”或“坏工作”,类似于人的训练方式。狗做个把戏。沃内尔说,研究人员扩展了该领域的早期工作,以便对目前可以通过图像看到世界的机器人或计算机程序进行这种训练,这是设计可在现实世界中运行的学习代理的重要的第一步。
人工智能中的许多当前技术要求机器人长时间与环境交互,以学习如何最佳地执行任务。在此过程中,代理可能会执行不仅是错误的操作(例如,机器人撞到墙壁上),而且还会发生灾难性的操作(例如,机器人在悬崖边上奔跑)。沃内尔说,人类的帮助将加快代理商的步伐,并帮助他们避免潜在的陷阱。
第一步,研究人员通过将其与15分钟人工提供的反馈一起使用来证明Deep TAMER的成功,该反馈可训练代理在Atari保龄球比赛中表现得比人类更好。人工智能中最先进的方法。接受过TAMER训练的特工表现出超人的能力,不仅击败了他们的业余教练,而且平均击败了专业的Atari球员。
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")